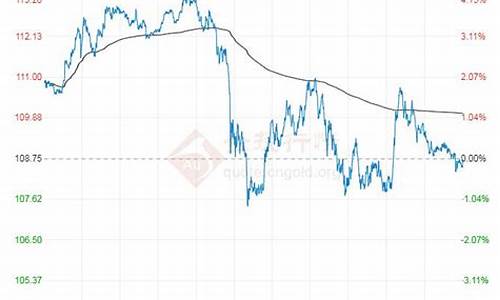
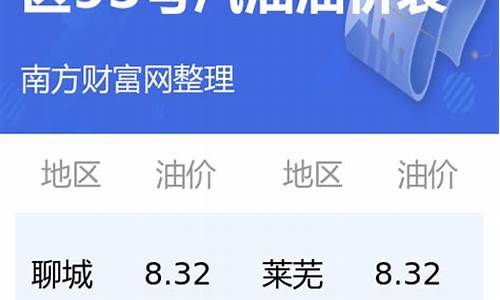
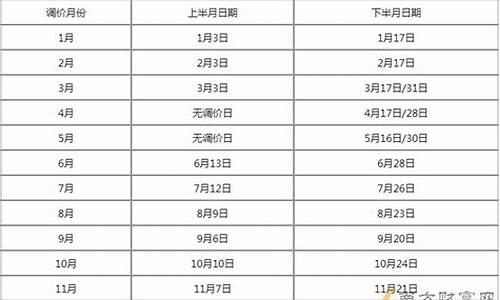
油价算法谁制定的依据有哪些_油价算法谁制定的依据有哪些规定
1.系统管理
2.#美国油价# 每加仑3.88美元,合成人民币多少钱一升?谁帮我算算
3.我想知道队列算法能干什么

最短路径dijkstra算法如下:
Dijkstra迪杰斯特拉是一种处理单源点的最短路径算法,就是说求从某一个节点到其他所有节点的最短路径就是Dijkstra。
资料拓展:
迪杰斯特拉算法(Dijkstra)是由荷兰数腔计算机科学家狄克斯特拉于1959年提出的,因此又叫狄克斯特拉算法。是从一个顶点到其薯纳衫余各顶点的最短路径算法,解决的是有权图中最短路径问题。
迪杰斯特拉算法主要特点是从起始点开始,用贪心算法的策略,每次遍历到始点距离最近且未访问过的顶点的邻接节点,直到扩展到终点为止。
Dijkstra算法一般的表述通常有两种方式,一种用永久和临时标号方式,一种是用OPEN,CLOSE表的方式,这里均用永久和临时标号的方式。注意该算法要求图中不存在负权边。
将T中顶点按递增的次序加入到S中,保证:从源点V0到S中其他各顶点的长度都不大于从V0到T中任何顶点的最短路径长度。每个顶点对应一个距离值。
S中顶点:从V0到此顶点的长度。T中顶点:从V0到此顶点的只包括S中顶点作中间顶点的最短路径长度。依据:可以证明V0到T中顶点Vk的,或是从V0到Vk的直接路径的权值;或是从V0经S中顶点到Vk的路径权值之和。
初始时令S={V0},T=V-S={其余顶点},T中顶点对应的距离值。若茄搭存在,d(V0,Vi)为弧上的权值。若不存在,d(V0,Vi)为∞。
从T中选取一个与S中顶点有关联边且权值最小的顶点W,加入到S中。对其余T中顶点的距离值进行修改:若加进W作中间顶点,从V0到Vi的距离值缩短,则修改此距离值。重复上述步骤2、3,直到S中包含所有顶点,即W=Vi为止。
系统管理
数据挖掘核心算法之一--回归
回归,是一个广义的概念,包含的基本概念是用一群变量预测另一个变量的方法,白话就是根据几件事情的相关程度,用其中几件来预测另一件事情发生的概率,最简单的即线性二变量问题(即简单线性),例如下午我老婆要买个包,我没买,那结果就是我肯定没有晚饭吃;复杂一点就是多变量(即多元线性,这里有一点要注意的,因为我最早以前犯过这个错误,就是认为预测变量越多越好,做模型的时候总希望选取几十个指标来预测,但是要知道,一方面,每增加一个变量,就相当于在这个变量上增加了误差,变相的扩大了整体误差,尤其当自变量选择不当的时候,影响更大,另一个方面,当选择的俩个自变量本身就是高度相关而不独立的时候,俩个指标相当于对结果造成了双倍的影响),还是上面那个例子,如果我丈母娘来了,那我老婆就有很大概率做饭;如果在加一个,如果我老丈人也来了,那我老婆肯定会做饭;为什么会有这些判断,因为这些都是以前多次发生的,所以我可以根据这几件事情来预测我老婆会不会做晚饭。
大数据时代的问题当然不能让你用肉眼看出来,不然要海量计算有啥用,所以除了上面那俩种回归,我们经常用的还有多项式回归,即模型的关系是n阶多项式;逻辑回归(类似方法包括决策树),即结果是分类变量的预测;泊松回归,即结果变量代表了频数;非线性回归、时间序列回归、自回归等等,太多了,这里主要讲几种常用的,好解释的(所有的模型我们都要注意一个问题,就是要好解释,不管是参数选择还是变量选择还是结果,因为模型建好了最终用的是业务人员,看结果的是老板,你要给他们解释,如果你说结果就是这样,我也不知道问什么,那升职加薪基本无望了),例如你发现日照时间和某地葡萄销量有正比关系,那你可能还要解释为什么有正比关系,进一步统计发现日照时间和葡萄的含糖量是相关的,即日照时间长葡萄好吃,另外日照时间和产量有关,日照时间长,产量大,价格自然低,结果是又便宜又好吃的葡萄销量肯定大。再举一个例子,某石油产地的咖啡销量增大,国际油价的就会下跌,这俩者有关系,你除了要告诉领导这俩者有关系,你还要去寻找为什么有关系,咖啡是提升工人精力的主要饮料,咖啡销量变大,跟踪发现工人的工作强度变大,石油运输出口增多,油价下跌和咖啡销量的关系就出来了(单纯的例子,不要多想,参考了一个根据遥感信息获取船舶信息来预测粮食价格的真实案例,感觉不够典型,就换一个,实际油价是人为操控地)。
回归利器--最小二乘法,牛逼数学家高斯用的(另一个法国数学家说自己先创立的,不过没办法,谁让高斯出名呢),这个方法主要就是根据样本数据,找到样本和预测的关系,使得预测和真实值之间的误差和最小;和我上面举的老婆做晚饭的例子类似,不过我那个例子在不确定的方面只说了大概率,但是到底多大概率,就是用最小二乘法把这个关系式写出来的,这里不讲最小二乘法和公式了,使用工具就可以了,基本所有的数据分析工具都提供了这个方法的函数,主要给大家讲一下之前的一个误区,最小二乘法在任何情况下都可以算出来一个等式,因为这个方法只是使误差和最小,所以哪怕是天大的误差,他只要是误差和里面最小的,就是该方法的结果,写到这里大家应该知道我要说什么了,就算自变量和因变量完全没有关系,该方法都会算出来一个结果,所以主要给大家讲一下最小二乘法对数据集的要求:
1、正态性:对于固定的自变量,因变量呈正态性,意思是对于同一个答案,大部分原因是集中的;做回归模型,用的就是大量的Y~X映射样本来回归,如果引起Y的样本很凌乱,那就无法回归
2、独立性:每个样本的Y都是相互独立的,这个很好理解,答案和答案之间不能有联系,就像掷硬币一样,如果第一次是反面,让你预测抛两次有反面的概率,那结果就没必要预测了
3、线性:就是X和Y是相关的,其实世间万物都是相关的,蝴蝶和龙卷风(还是海啸来着)都是有关的嘛,只是直接相关还是间接相关的关系,这里的相关是指自变量和因变量直接相关
4、同方差性:因变量的方差不随自变量的水平不同而变化。方差我在描述性统计量分析里面写过,表示的数据集的变异性,所以这里的要求就是结果的变异性是不变的,举例,脑袋轴了,想不出例子,画个图来说明。(我们希望每一个自变量对应的结果都是在一个尽量小的范围)
我们用回归方法建模,要尽量消除上述几点的影响,下面具体讲一下简单回归的流程(其他的其实都类似,能把这个讲清楚了,其他的也差不多):
first,找指标,找你要预测变量的相关指标(第一步应该是找你要预测什么变量,这个话题有点大,涉及你的业务目标,老板的目的,达到该目的最关键的业务指标等等,我们后续的话题在聊,这里先把方法讲清楚),找相关指标,标准做法是业务专家出一些指标,我们在测试这些指标哪些相关性高,但是我经历的大部分公司业务人员在建模初期是不靠谱的(真的不靠谱,没思路,没想法,没意见),所以我的做法是将该业务目的所有相关的指标都拿到(有时候上百个),然后跑一个相关性分析,在来个主成分分析,就过滤的差不多了,然后给业务专家看,这时候他们就有思路了(先要有东西激活他们),会给一些你想不到的指标。预测变量是最重要的,直接关系到你的结果和产出,所以这是一个多轮优化的过程。
第二,找数据,这个就不多说了,要么按照时间轴找(我认为比较好的方式,大部分是有规律的),要么按照横切面的方式,这个就意味横切面的不同点可能波动较大,要小心一点;同时对数据的基本处理要有,包括对极值的处理以及空值的处理。
第三, 建立回归模型,这步是最简单的,所有的挖掘工具都提供了各种回归方法,你的任务就是把前面准备的东西告诉计算机就可以了。
第四,检验和修改,我们用工具计算好的模型,都有各种设检验的系数,你可以马上看到你这个模型的好坏,同时去修改和优化,这里主要就是涉及到一个查准率,表示预测的部分里面,真正正确的所占比例;另一个是查全率,表示了全部真正正确的例子,被预测到的概率;查准率和查全率一般情况下成反比,所以我们要找一个平衡点。
第五,解释,使用,这个就是见证奇迹的时刻了,见证前一般有很久时间,这个时间就是你给老板或者客户解释的时间了,解释为啥有这些变量,解释为啥我们选择这个平衡点(是因为业务力量不足还是其他的),为啥做了这么久出的东西这么差(这个就尴尬了)等等。
回归就先和大家聊这么多,下一轮给大家聊聊主成分分析和相关性分析的研究,然后在聊聊数据挖掘另一个利器--聚类。
#美国油价# 每加仑3.88美元,合成人民币多少钱一升?谁帮我算算
系统的用户包括普通用户和管理员用户两大类。
对于普通用户,系统需要向其提供只读的访问权限,可以查看系统内预定义好的各类风险GIS展示,风险评价指标体系、评价结果,以及不同评价对象的基本信息,另外还可以对系统内的模型运行结果进行查看。
图5.74增加评价方案页面
图5.75修改评价方案页面
图5.76同级指标审核页面
图5.77批量评价页面
管理员用户则需要为系统各模块的正常运行和系统内各种数据的维护等提供支持,系统管理平台的用户对象仅是系统管理员。
系统管理的开发将主要围绕系统管理平台、数据管理和图库管理3方面展开。系统管理平台主要是对整个网站系统的后台管理和网站设置,即实现该原型系统的后台维护。数据管理主要包括油价数据、管理,以及基础数据管理。另外,图库管理是针对国家、运输等相关风险中所用到的结构图或地图等进行集中管理。
5.4.5.1系统管理平台开发
以B/S形式运行的风险管理系统的管理平台如图5.78所示。依照数据流程的线索将系统整体功能从左到右进行组织,划分为数据准备、数据处理、数据存储和数据应用四大块,每一块中包括了数据流程不同阶段的具体任务。这些任务以多种形式展现在管理平台界面中,包括中心的流程图形式,左侧菜单和顶层菜单,对系统的管理功能提供了多个访问入口,方便系统管理员对系统功能的把握和调用。
接下来,以主界面中的数据流程图为主线,简单介绍该原型系统的逻辑框架。在系统运行管理平台界面的数据准备中,将系统需要获取的数据分为Internet抽取的价格数据和风险评价数据两大类(见图5.63c)。
在数据处理部分,系统提供对油价数据的进一步整理和数据自动抓取过程中的日志查看,保证系统提供准确完整的数据(见图5.63d)。除此以外,系统管理的数据处理部分包含模型运算模块的调用和管理,以及系统对指标体系和对象评价相关数据的管理。
图5.78系统管理主界面
目前主要介绍的是国家风险、市场风险和运输风险3个子功能模块。此外,除了上面所介绍的系统管理主要框架以外,在系统管理平台中,还添加了系统设置和网站操作模块。系统设置和网站操作主要实现整个原型系统的后台界面框架管理。具体主要包含以下几个方面。
1)直接利用取Sharepoint列表功能对网站后台框架进行整体设计,可以进行创建、编辑网页、网站框架设计(图5.79)。
图5.79网站操作
2)更改网站主题。网站后台中有多种网站主题,用户可根据需要选择不同的主题(图5.80)。
3)在每一个系统模块下面,可进行整体页面和架构的设计,同时可以编辑相应的超链接条目(图5.81)。
4)在网站设置主页中,高级用户可以进行权限管理,主题外观设置,系统库的管理以及网站集的管理(图5.82)。当然,上述权限操作仅限于高级用户。
5.4.5.2数据管理的开发
数据管理包括油价数据和管理、基础数据管理等内容。在油价数据和管理中主要完成油价数据和的自动抓取功能,基础数据管理将对各个风险模块评价对象的概况、信息等相关数据进行维护和管理。
(1)油价数据和管理
油价数据和管理的重点是油价和时间数据的获取。系统要求能够实现从Internet中定期自动地抓取数据并存储到系统中心数据库中。
图5.80网站主题更改
图5.81编辑网页
图5.82网站设置
考虑到数据管理和数据库之间的关系比较密切,并且需要不间断地运行,所以对数据管理模块的界面取了C/S的开发形式。
自动抓取模块的开发内容包括:价格数据抓取算法的设计;抓取算法的设计;数据抽取任务控制的整体程序结构确定;任务的自动执行和调度算法的设计;日志功能的使用,要能够依据日志对任务执行中的错误追踪和出错原因进行判断;需要实现任务失败重试,并可以设置重试次数阈值,默认为3次等。
1)调度算法。将抽取代码进行封装,添加调度日志等功能,设计出自动抓取模块流程的整体流程图(图5.83,图5.84)。用于数据管理的管理员界面如图5.85所示。
图5.83自动抓取模块流程图
图5.84自动抓取模块流程图
图5.85数据管理模块界面
2)价格数据抓取算法。自动抓取模块的核心代码是价格数据抓取和抓取算法。价格数据抓取从网页中抓取数据存储到本地中来,包括下载模块和处理转换模块两个子模块。自动抓取模块的核心代码部分自动远程下载价格数据,并按照指定路径保存到本地,并将下载结果计人数据库下载日志表,然后将下载下来的Excel表格数据进行转换,转换成符合数据库所建立的表格形式。
对美国能源部的数据抓取代码流程和表格处理转换流程如图5.86与图5.87所示。
图5.86数据抓取代码流程图
图5.87表格处理转换流程图
价格数据抓取模块的技术难点主要有:所下载的表格中包含的市场名称可能会发生变动,难以预期,导致匹配失败;Excel表格中产品名称、市场名称、价格类型、货币类型这几个字段是合并在一起的,需要将其分别识别出来;原表格中的日期格式直接导入数据库会发生不一致现象,需要对其进行转换处理。这些难点的解决主要依赖与算法的设计,在此不再赘述。
3)数据抓取算法。数据抓取算法要求对美国能源部上关于油品的所有历史进行抓取,并保存进数据库。具体实现算法是从美国能源部指定的网站上将页面的源码下载到本地,然后进行相关字符串抓取、清洗、操作之后进入中心数据库。
抓取算法的技术难点,主要在于是基于页面HTML形式而非链接,另外抓取的要符合数据库规定的形式。解决这些问题的主要方法包括对网页本地化装载的控件进行恰当的选择;在去除页面的HTML标记之后需要附加一些更正性质的处理,比如日期、年份的选择,日期、时间和内容之间没有空格的判断问题等;最后,最主要的就是在抓取中大量使用正则表达式提高效率。页面的呈现,如图5.88所示。
图5.88国际油价
(2)基础数据管理
系统管理平台主要实现基础数据管理。在基础数据管理模块,基于可扩展的数据维护技术,完成了总体架构设计,以国家、运输、市场基础数据为例的基础数据管理功能实现。在基础信息管理下实现了概况、信息、油价、等的添加、编辑、修改、更新一系列操作。
在基础数据管理中,实现了国家数据的概况、基本信息的页面设计;运输数据的港口、航线概况和基本信息的页面设计;市场数据管理的页面设计,并都实现了链库功能。
图5.63d展示的是系统管理的主界面。其中,最主要的功能是实现基础数据管理操作,该模块仅对高级用户(即有权限进行数据维护的用户)开放。
1)国家数据管理。与风险评价页面相类似,基础数据部分根据模块分了“国家数据”“运输数据”等标签,各标签下又有各自模块的细分功能菜单,显示于页面左侧。国家数据的新增国家和概况展示的页面,如图5.89和图5.90所示。
图5.89新增国家页面
图5.90国家基本信息批量展示
2)运输数据管理。运输数据管理模块实现了港口概况、港口信息、航线概况、航线信息的页面设计。现仅以港口信息页面展示为例,如图5.91所示。
5.4.5.3图库管理
在整个风险评价系统中,应用了大量来丰富展现评价对象的相关信息。的应用范围包括:国家对象的地理分布示意以及国家的内部行政划分等;港口对象的标志性,可能是港口的照片或者结构图等;以及其他模块所应用到的。
在图库管理部分,目前考虑的有国家和港口的管理。图库的结构如图5.92所示。
图5.91港口信息维护
图5.92图库管理结构图
图5.93是添加的页面。
图5.94是国家对象图库的显示页面,图5.95是一个具体的对象页面,并且可以在此处删除或者修改。
图5.93图库管理-添加
图5.94图库管理-国家对象图库
图5.95图库管理-国家对象具体显示
我想知道队列算法能干什么
1加仑=3.785公升
3.88美元=25.244人民币
25.244/3.785=6.67元/公升
事实上美国的汽油和中国的汽油没有可比性,汽油标号算法不同,中国的汽油号的油品还不如美国的87号(入门级)汽油
队列是一种先进先出的数据结构,由于这一规则的限制,使得队列有区别于栈等别的数据结构。
作为一种常用的数据结构,同栈一样,是有着丰富的现实背景的。以下是几个典型的例子。
[例5-2] 一个旅行家想驾驶汽车以最少的费用从一个城市到另一个城市(设出发时油箱是空的).给定两个城市之间的距离D1,汽车油箱的容量C(以升为单位),每升汽油能行驶的距离D2,出发点每升汽油价格P和沿途油站数N(N可以为零),油站i离出发点的距离Di,每升汽油价格Pi(i=1,2,……N).
计算结果四舍五入至小数点后两位.
如果无法到达目的地,则输出"No Solution".
样例:
INPUT
D1=275.6 C=11.9 D2=27.4 P=2.8 N=2
油站号I
离出发点的距离Di
每升汽油价格Pi
1
102.0
2.9
2
220.0
2.2
OUTPUT
26.95(该数据表示最小费用)
[问题分析]
看到这道题,许多人都马上判断出穷举是不可行的,因为数据都是以实数的形式给出的.但是,不用穷举,有什么方法是更好的呢 递推是另一条常见的思路,但是具体方法不甚明朗.
既然没有现成的思路可循,那么先分析一下问题不失为一个好办法.由于汽车是由始向终单向开的,我们最大的麻烦就是无法预知汽车以后对汽油的需求及油价变动;换句话说,前面所买的多余的油只有开到后面才会被发觉.
提出问题是解决的开始.为了着手解决遇到的困难,取得最优方案,那就必须做到两点,即只为用过的汽油付钱;并且只买最便宜的油.如果在以后的行程中发现先前的某些油是不必要的,或是买贵了,我们就会说:"还不如当初不买."由这一个想法,我们可以得到某种启示:设我们在每个站都买了足够多的油,然后在行程中逐步发现哪些油是不必要的,以此修改我们先前的购买,节省资金;进一步说,如果把在各个站加上的油标记为不同的类别,我们只要在用时用那些最便宜的油并为它们付钱,其余的油要么是太贵,要么是多余的,在最终的中会被排除.要注意的是,这里的便宜是对于某一段路程而言的,而不是全程.
[算法设计]由此,我们得到如下算法:从起点起(包括起点),每到一个站都把油箱加满(终点除外);每经过两站之间的距离,都按照从便宜到贵的顺序使用油箱中的油,并计算花费,因为这是在最优方案下不得不用的油;如果当前站的油价低于油箱中仍保存的油价,则说明以前的购买是不够明智的,其效果一定不如购买当前加油站的油,所以,明智的选择是用本站的油代替以前购买的高价油,留待以后使用,由于我们不是真的开车,也没有为备用的油付过钱,因而这样的反悔是可行的;当我们开到终点时,意味着路上的费用已经得到,此时剩余的油就没有用了,可以忽略.
数据结构用一个队列:存放由便宜到贵的各种油,一个头指针指向当前应当使用的油(最便宜的油),尾指针指向当前可能被替换的油(最贵的油).在一路用一路补充的过程中同步修改数据,求得最优方案.
注意:每到一站都要将油加满,以确保在有解的情况下能走完全程.并设出发前油箱里装满了比出发点贵的油,将出发点也看成一站,则程序循环执行换油,用油的操作,直到到达终点站为止.
本题的一个难点在于认识到油箱中油的可更换性,在这里,突破现实生活中的思维模式显得十分重要.
[程序清单]
program ex5_2(input,output);
const max=1000;
type recordtype=record price,content:real end;
var i,j,n,point,tail:longint;
content,change,distance2,money,use:real;
price,distance,consume:array[0..max] of real;
oil:array [0..max] of recordtype;
begin
write('Input DI,C,D2,P:'); readln(distance[0],content,distance2,price[0]);
write('Input N:'); readln(n); distance[n+1]:=distance[0];
for i:=1 to n do
begin
write('Input D[',i,'],','P[',i,']:');
readln(distance[i],price[i])
end;
distance[0]:=0;
for i:=n downto 0 do consume[i]:=(distance[i+1]-distance[i])/distance2;
for i:=0 to n do
if consume[i]>content then
begin writeln('No Solution'); halt end;
money:=0; tail:=1; change:=0;
oil[tail].price:=price[0]*2; oil[tail].content:=content;
for i:=0 to n do
begin
point:=tail;
while (point>=1) and (oil[point].price>=price[i]) do
begin
change:=change+oil[point].content;
point:=point-1
end;
tail:=point+1;
oil[tail].price:=price[i];
oil[tail].content:=change;
use:=consume[i]; point:=1;
while (use>1e-6) and (point=oil[point].content
then begin use:=use-oil[point].content;
money:=money+oil[point].content*oil[point].price;
point:=point+1 end
else begin oil[point].content:=oil[point].content-use;
money:=money+use*oil[point].price;
use:=0 end;
for j:=point to tail do oil[j-point+1]:=oil[j];
tail:=tail-point+1;
change:=consume[i]
end;
writeln(money:0:2)
end.
[例5-3] 分油问题:设有大小不等的3个无刻度的油桶,分别能够存满,X,Y,Z公升油(例如X=80,Y=50,Z=30).初始时,第一个油桶盛满油,第二,三个油桶为空.编程寻找一种最少步骤的分油方式,在某一个油桶上分出targ升油(例如targ=40).若找到解,则将分油方法打印出来;否则打印信息"UNABLE"等字样,表示问题无解.
[问题分析] 这是一个利用队列方法解决分油问题的程序.分油过程中,由于油桶上没有刻度,只能将油桶倒满或者倒空.三个油桶盛满油的总量始终等于开始时的第一个油桶盛满的油量.
[算法设计] 分油程序的算法主要是,每次判断当前油桶是不是可以倒出油,以及其他某个油桶是不是可以倒进油.如果满足以上条件,那么当前油桶的油或全部倒出,或将另一油桶倒满,针对两种不同的情况作不同的处理.
程序中使用一个队列Q,记录每次分油时各个油桶的盛油量和倾倒轨迹有关信息,队列中只记录互不相同的盛油状态(各个油桶的盛油量),如果程序列举出倒油过程的所有不同的盛油状态,经考察全部状态后,未能分出TARG升油的情况,就确定这个倒油问题无解.队列Q通过指针front和rear实现倒油过程的控制.
[程序清单]
program ex5_3(input,output);
const maxn=5000;
type stationtype=array[1..3] of integer;
elementtype=record
station:stationtype;
out,into:1..3;
father:integer
end;
queuetype=array [1..maxn] of elementtype;
var current,born:elementtype;
q:queuetype;
full,w,w1:stationtype;
i,j,k,remain,targ,front,rear:integer;
found:boolean;
procedure addQ(var Q:queuetype;var rear:integer; n:integer; x:elementtype);
begin
if rear=n
then begin writeln('Queue full!'); halt end
else begin rear:=rear+1; Q[rear]:=x end
end;
procedure deleteQ(var Q:queuetype;var front:integer;rear,n:integer;var x:elementtype);
begin
if front=rear
then begin writeln('Queue empty!'); halt end
else begin front:=front+1; x:=Q[front] end
end;
function dup(w:stationtype;rear:integer):boolean;
var i:integer;
begin
i:=1;
while (i<=rear) and ((w[1]q[i].station[1]) or
(w[2]q[i].station[2]) or (w[3]q[i].station[3])) do i:=i+1;
if i0 then
begin
print(q[k].father);
if k>1 then write(q[k].out, ' TO ',q[k].into,' ')
else write(' ':8);
for i:=1 to 3 do write(q[k].station[i]:5);
writeln
end
end;
begin {Main program}
writeln('1: ','2: ','3: ','targ');
readln(full[1],full[2],full[3],targ);
found:=false;
front:=0; rear:=1;
q[1].station[1]:=full[1];
q[1].station[2]:=0;
q[1].station[3]:=0;
q[1].father:=0;
while (front begin
deleteQ(q,front,rear,maxn,current);
w:=current.station;
for i:=1 to 3 do
for j:=1 to 3 do
if (ij) and (w[i]>0) and (w[j]remain
then begin w1[j]:=full[j]; w1[i]:=w[i]-remain end
else begin w1[i]:=0; w1[j]:=w[j]+w[i] end;
if not(dup(w1,rear)) then
begin
born.station:=w1;
born.out:=i;
born.into:=j;
born.father:=front;
addQ(q,rear,maxn,born);
for k:=1 to 3 do
if w1[k]=targ then found:=true
end
end
end;
if not(found)
then writeln('Unable!')
else print(rear)
end.
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。